00:12:25
AI的能源胃口:训练与运行一个大型语言模型的真实成本
全球数据中心运行的前沿AI模型,如GPT、Grok、Claude和Gemini,拥有一个共同需求——巨大的能源。要理解其能源需求的规模,我们需要从剖析训练一个大型语言模型(LLM)开始,进而审视整个行业。
训练GPT-4的能源账本
由于大多数私营公司不公布其AI模型的确切能耗数据,我们以通过估算可部分了解的OpenAI GPT-4作为分析样本。
据估算,拥有1.7万亿参数的GPT-4,其预训练过程处理了约13万亿个令牌(tokens),需要执行约20*10²⁴(20 septillion)次浮点运算。为了完成这项壮举,OpenAI可能动用了高达25,000块Nvidia A100 GPU,持续训练了约3个月。
关键数据点:
- 单块A100 GPU功耗:~400瓦
- 总GPU数量:~25,000块
- 总训练时间:~90天
并行计算:如何驾驭25,000块GPU
让如此庞大的GPU集群协同工作,核心挑战在于高效的并行化训练策略。这类似于指挥25,000名厨师同时制作一道大餐,需要精密的组织。
AI训练的核心是矩阵乘法(Matrix Multiplications)运算。对于大型语言模型,通常采用三种并行策略:
- 张量并行(Tensor Parallelism):利用NVIDIA的NVLink协议,将单个大运算(如100,000x100,000的矩阵乘法)拆分到一组(通常是8块)GPU上并行计算。8块A100 GPU可组成一个NVIDIA HGX服务器,功耗约3-6 kW。
- 流水线并行(Pipeline Parallelism):根据模型架构(如GPT-4估计有120层网络)进行划分,将不同的层组分配给不同的HGX服务器组处理。
- 数据并行(Data Parallelism):复制多个相同的模型实例,同时处理训练数据的不同批次,最后通过梯度算法同步更新模型参数。
通过组合这些策略,一个GPT-4实例理论上可在120块GPU上运行。OpenAI的25,000块GPU因此可以创建约200个模型复制品并行训练,充分利用所有计算资源。
训练能耗:一个小城市的月耗电量
基于上述计算框架,我们可以估算GPT-4训练的总能耗:
- 所需HGX服务器数量:~3,125台(25,000 GPUs / 8 GPUs per server)
- 单台服务器功耗:~6.5 kW
- 总训练时间:90天 * 24小时
计算得出,总能耗约为44,000兆瓦时(MWh),即44吉瓦时(GWh)。这个量级相当于一个约5万人口的小城市一个月的总用电量。
值得注意的是,还需考虑数据中心的冷却开销,通常用电力使用效率(PUE)衡量。若PUE为1.2,实际总能耗将增至约52.8 GWh。
推理能耗:运行模型的成本可能更高
训练只是故事的一部分。将训练好的模型部署上线(推理)供用户使用,其长期能源需求可能远超训练阶段。
以ChatGPT为例:
- 预计周活跃用户超7亿
- 日均处理提示(prompts)超25亿次
- 单次查询(提示)估算能耗:~0.3瓦时(Wh)(因任务类型而异)
据此计算,单日推理能耗就高达750兆瓦时(MWh)。服务90天的总推理能耗估算约为67吉瓦时(GWh)(考虑PUE后则超80 GWh),已高于其训练总能耗。况且AI公司通常需同时维护和服务多个模型版本,进一步推高总能耗。
全球竞赛与能源基础设施挑战
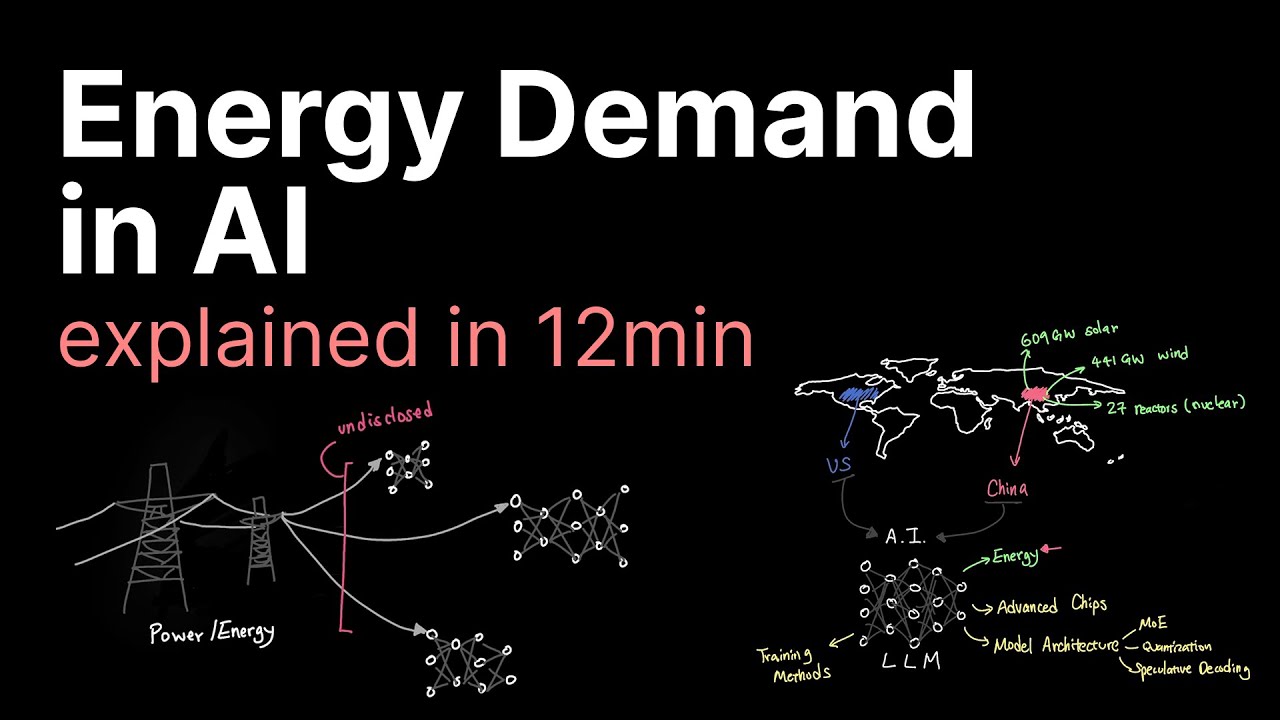
2023年,全球数据中心总耗电约176太瓦时(TWh),占美国总用电量的4.4%。预测到2030年,这一比例可能攀升至8-10%,AI是重要推手。
为满足激增的能源需求,科技巨头各显神通:
- xAI:购买30台甲烷涡轮机为孟菲斯的Colossus设施供电。
- OpenAI:计划建设耗资巨大的“星门”(Stargate)数据中心,容量高达5吉瓦(GW),可支持40万个GB200 GPU。
- Meta:自建天然气发电厂。
- Google:扩展其超大规模数据中心。
然而,在美国,这些项目常面临地方监管、环保质疑和基础设施承压等挑战,导致许可受阻甚至法律诉讼。
对比之下,中国的能源建设更多地由国家层面 centralized 主导。2023年,中国新增光伏装机609吉瓦,风电装机441吉瓦,并有27座核反应堆在建,能源产能快速扩张,被视为可能在AI竞赛中提供强大的能源基础保障。
未来之路:能效提升与能源供给
尽管能源需求巨大,但其并非创新的唯一瓶颈。以下技术有助于降低AI的能源成本:
- 先进芯片:如NVIDIA Blackwell架构的GB200,性能与能效提升。
- 模型架构优化:混合专家(MoE)、量化(Quantization)、推测解码(Speculative Decoding)。
- 训练方法改进:更高效的算法。
但最终,充足、稳定的能源供给——包括更多发电能力、更强大的电网和更高效的芯片冷却系统——将是支撑AI持续创新的底层基石,并可能影响全球AI竞争的最终格局。


















